Un test est sans biais si \(1 - \beta \ge \alpha\) (Puissance \(\ge\) Niveau de test)
\(T_1\) est plus puissant que \(T_2\) si pour un même niveau de test \(\alpha\), \(1 - \beta_1 \ge 1 - \beta_2\)
3 Etude d’un cas concret
🎯 Objectif : nous souhaitons tester si une pièce est non truquée.
Nous utiliserons une loi de Bernoulli pour modéliser nos lancers, avec par exemple :
pile : 1
face : 0
set.seed(1986)n <-100# nombre de lancersp <-0.5# Probabilité d'avoir un pile# Simulation de n lancersX <-rbinom(n, 1, prob = p)# Quelques statistiques descriptivestable(X)
X
0 1
49 51
prop.table(table(X))
X
0 1
0.49 0.51
mean(X)
[1] 0.51
var(X) # p * (1-p)
[1] 0.2524242
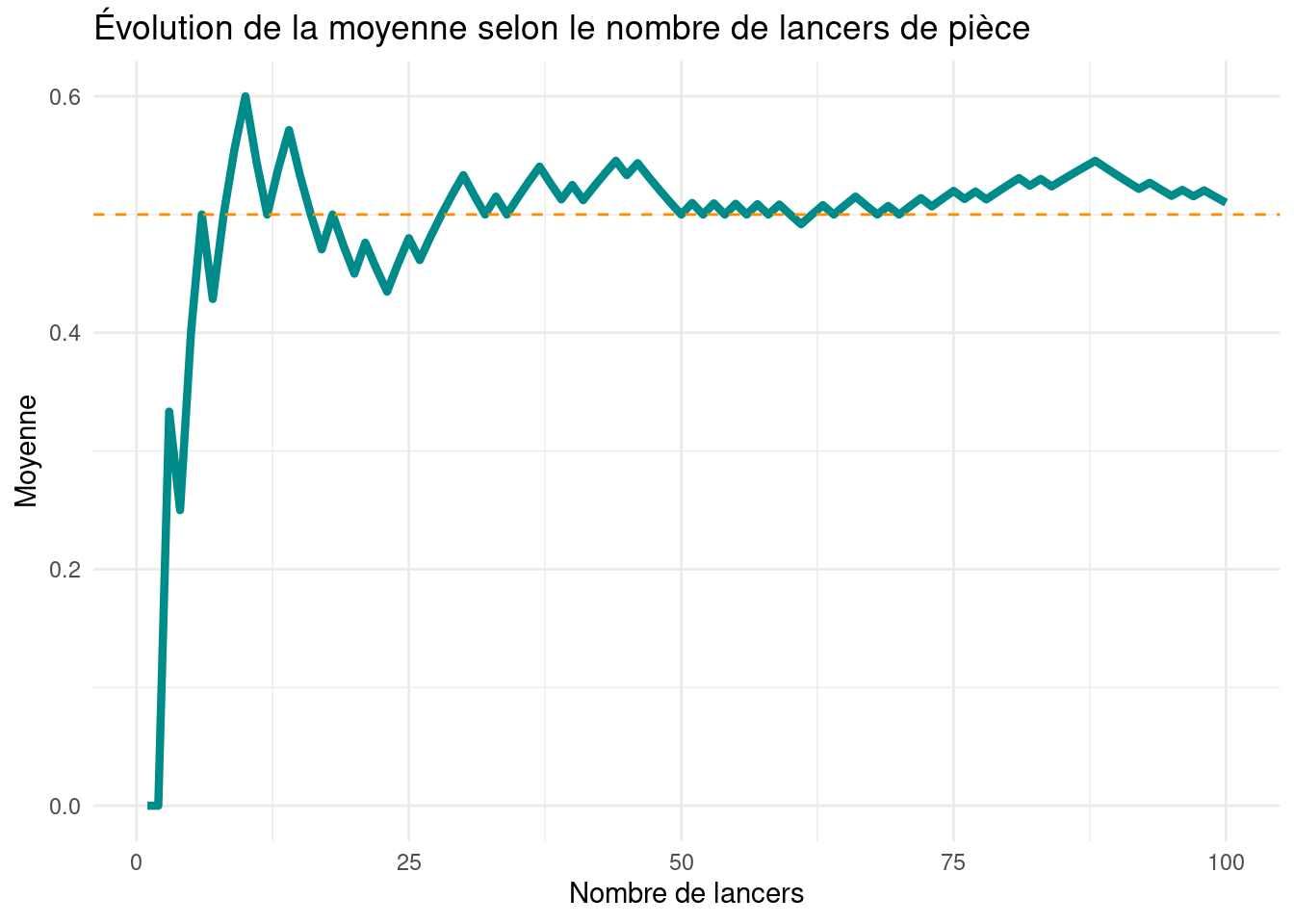
3.1 LFGN
La Loi Forte des Grands Nombres nous dit que :
plus nous augmentons le nombre de lancers
plus la moyenne empirique converge vers l’espérance
Calculons les moyennes cumulées et traçons l’évolution lorsque le nombre de lancers augmente
# Somme cumulative divisée par le nombre de lancers correspondantsx_bar <-cumsum(X) /seq_along(X)df <-data.frame(x =seq_along(x_bar), x_bar = x_bar)
Autre méthode pour calculer x_bar
x_bar <-rep(NA, n)for (i in1:n) { x_bar[i] <-sum(X[1:i]) / i}
Code ggplot
library(ggplot2)ggplot(df, aes(x, x_bar)) +geom_line(color ="darkcyan", linewidth =1.5) +geom_hline(yintercept = p, linetype ="dashed", color ="darkorange") +labs(x ="Nombre de lancers", y ="Moyenne", title ="Évolution de la moyenne selon le nombre de lancers de pièce") +theme_minimal()
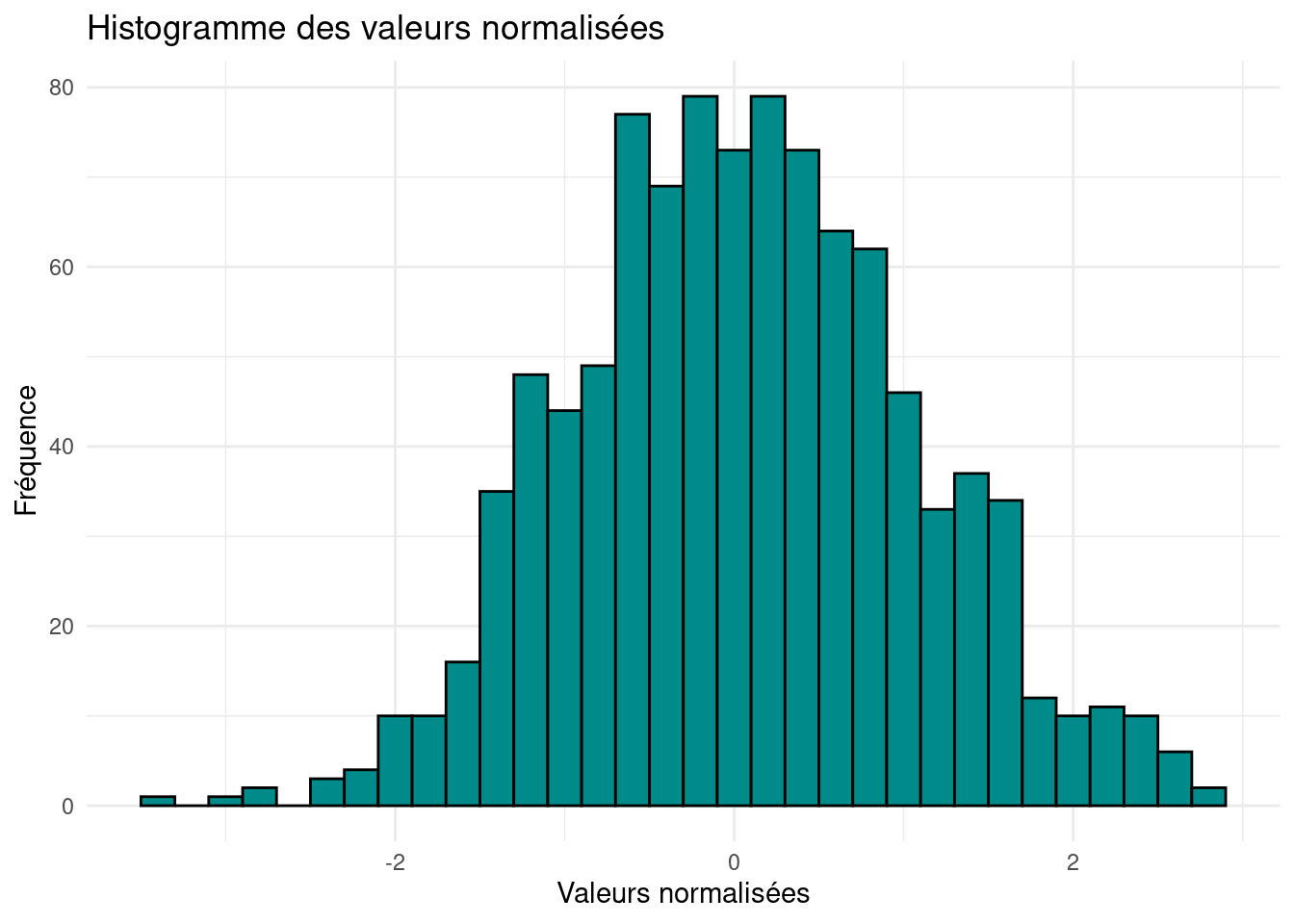
library(ggplot2)ggplot(data.frame(Y), aes(x = Y)) +geom_histogram(binwidth =0.20, color ="black", fill ="darkcyan") +labs(x ="Valeurs normalisées", y ="Fréquence", title ="Histogramme des valeurs normalisées") +theme_minimal()
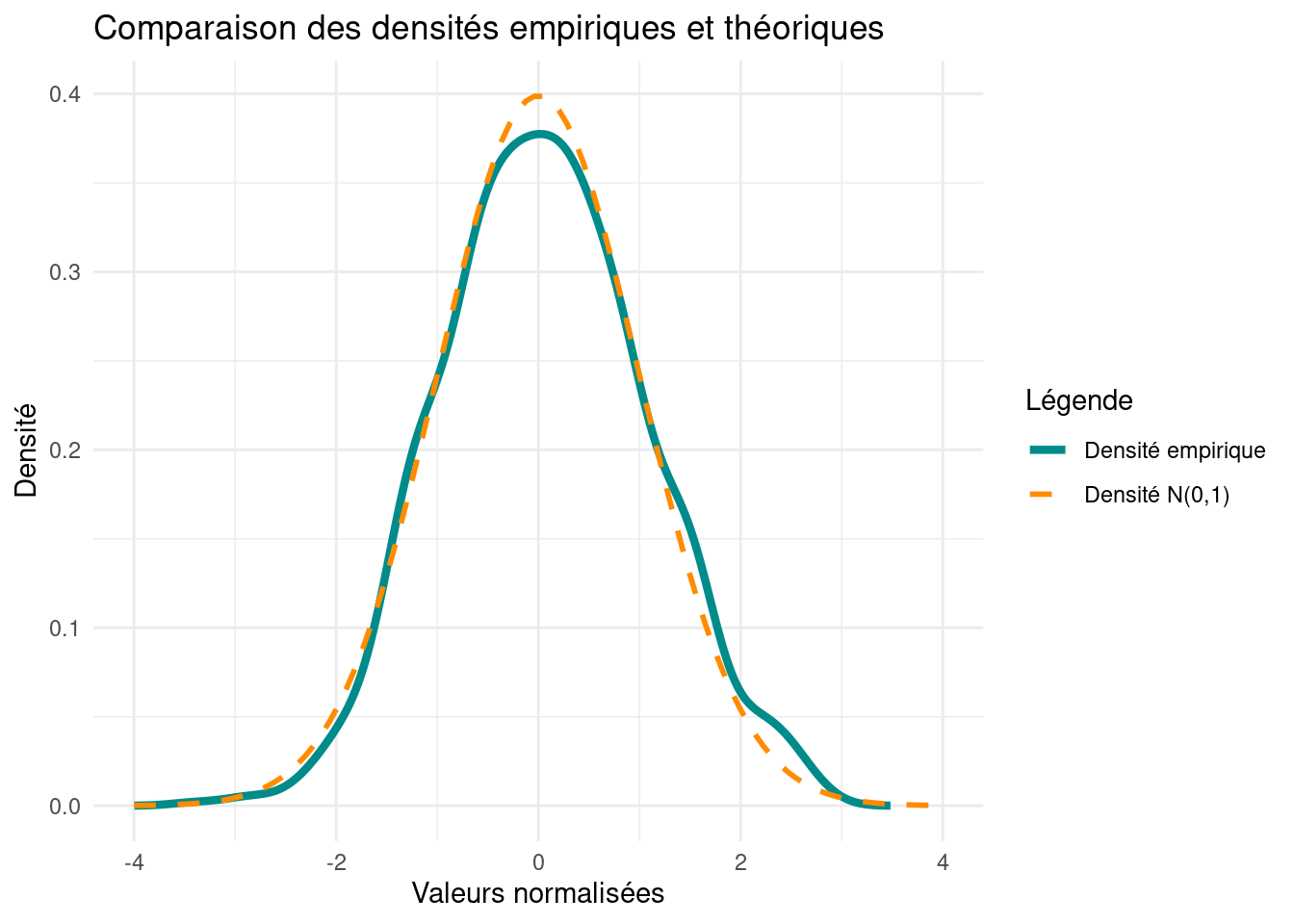
La distribution nous fait bien penser à la loi normale centrée réduite.
Code ggplot
density_Y <-density(Y)# Create data for standard normal density curvestd_norm_curve <-data.frame(x =seq(-4, 4, length.out =100),y =dnorm(seq(-4, 4, length.out =100)))legend_colors <-c("Densité empirique"="darkcyan", "Densité N(0,1)"="darkorange")# Create ggplot with density plot and standard normal density curveggplot() +geom_line(data =data.frame(x = density_Y$x, y = density_Y$y), aes(x, y, color ="Densité empirique"),linewidth =1.5) +geom_line(data = std_norm_curve, aes(x, y, color ="Densité N(0,1)"), linetype ="dashed", linewidth =1) +xlim(-4, 4) +labs(x ="Valeurs normalisées", y ="Densité", title ="Comparaison des densités empiriques et théoriques",color ="Légende") +scale_color_manual(values = legend_colors) +theme_minimal()
3.3 Mon premier test
Supposons que nous lançons 100 fois une pièce et que nous obtenons :
59 pile (1)
41 face (0)
n <-100nb_pile <-59X <-c(rep(1, nb_pile), rep(0, n - nb_pile))table(X)
X
0 1
41 59
Ok, il y a un écart significatif entre le nombre de piles et de faces, mais est-ce que cela signifie que la pièce est truquée ?
Nous allons établir un test pour voir si la moyenne empirique obtenue s’éloigne trop de la moyenne théorique.
Soit \(H_0\) : la pièce n’est pas truquée (p = 0.5)
Vs \(H_1\) : la pièce est truquée (p ≠ 0.5)
Nous définissons le niveau de risque\(\alpha\).
Un niveau de risque à 0.05 signifie que l’on veut être sûr à 95 % de ne pas rejeter \(H_0\) alors qu’elle est vraie.
alpha <-0.05p_hat <-mean(X)
Soit \(T\) la statistique de test
calculée à partir des données observées,
utilisée pour évaluer la plausibilité de l’hypothèse nulle
sert à quantifier l’écart entre les données observées et ce à quoi on s’attendrait si l’hypothèse nulle était vraie
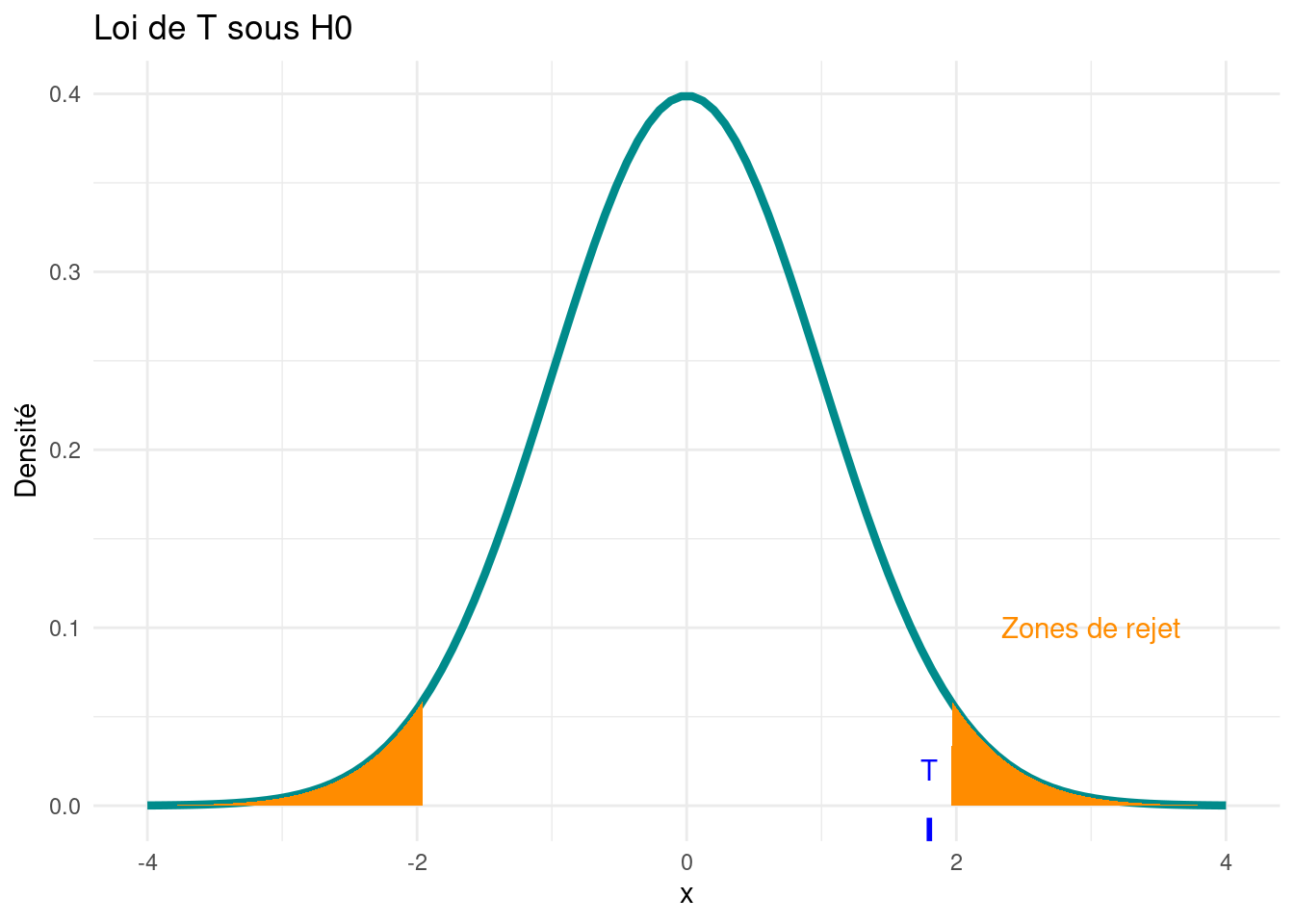
Sous \(H_0\), \(T\) suit une loi Normale Centrée Réduite :
nous définissons donc la zone de rejet
la zone de rejet est la région où les valeurs observées sont tellement extrêmes que notre hypothèse de départ semble fausse
nous rejetons \(H_0\) si T n’appartient pas à l’intervalle suivant
c(-1, 1) *qnorm(1- alpha /2)
[1] -1.959964 1.959964
Est-ce que l’on rejette \(H_0\) ?
Autrement dit, est-ce que \(T\) appartient à la zone de rejet ?
T <-qnorm(1- alpha /2) | T >qnorm(1- alpha /2)
[1] FALSE
On ne peut pas rejeter \(H_0\) au niveau de risque 0.05.
Représentation graphique :
Code ggplot
# Données pour la courbe de densité normalex_values <-seq(-4, 4, length.out =100)y_values <-dnorm(x_values)# Données pour les zones de rejetzone_rejet_gauche <-seq(-4, qnorm(alpha/2), 0.01)zone_rejet_droite <-seq(qnorm(1-alpha/2), 4, 0.01)# Création du graphique avec ggplot2ggplot() +geom_line(data =data.frame(x = x_values, y = y_values), aes(x, y), color ="darkcyan", linewidth =1.5) +geom_polygon(data =data.frame(x =c(zone_rejet_gauche, zone_rejet_gauche[length(zone_rejet_gauche)]), y =c(dnorm(zone_rejet_gauche), 0)), aes(x, y), fill ="darkorange") +geom_polygon(data =data.frame(x =c(zone_rejet_droite, zone_rejet_droite[length(zone_rejet_droite)]), y =c(0, dnorm(zone_rejet_droite))), aes(x, y), fill ="darkorange") +geom_rug(data =data.frame(T = T), aes(x = T), sides ="b", color ="blue", linewidth =1) +xlim(-4, 4) +labs(x ="x", y ="Densité", title ="Loi de T sous H0") +theme_minimal() +scale_fill_manual(values ="darkorange", guide =FALSE) +guides(color ="none") +annotate("text", x =3, y =0.1, label ="Zones de rejet", color ="darkorange") +annotate("text", x = T, y =0.02, label ="T", color ="blue") +theme(legend.position ="none")
Nous remarquons que \(T\) ne se trouve pas dans la zone de rejet
Si \(T\) se trouvait dans la zone de rejet, nous aurions affirmé qu’il est peu probable que \(T\) suive une \(\mathcal{N}(0, 1)\)
nous aurions donc rejeté \(H_0\)
3.4 p-valeur
Probabilité d’obtenir une valeur aussi extrême que celle observée
plus grande valeur possible de \(\alpha\) conduisant à ne pas rejeter \(H_0\)
p_val <-2* (1-pnorm(T)) ; p_val
[1] 0.07186064
La p-valeur vaut environs 11%. Cela signifie que si nous avions choisi un niveau de risque de :
10% : nous ne rejettons pas \(H_0\) et considérons que la pièce n’est pas truquée
12% : nous rejettons \(H_0\)
3.5 Test unilatéral
Jusqu’à maintenant, nous étions dans le cas d’un test bilatéral.
C’est à dire que nous testions pour déterminer si la pièce est truquée, sans nous préoccuper si elle avantage le côté pile ou le côté face.
Maintenant, imaginons que nous souhaitons tester si elle est truquée côté pile uniquement. Nous avons donc :
Soit \(H_0\) : la pièce n’est pas truquée (p = 0.5)
Vs \(H_1\) : la pièce est truquée côté pile (p > 0.5)
La statistique de test \(T\) ne change pas.
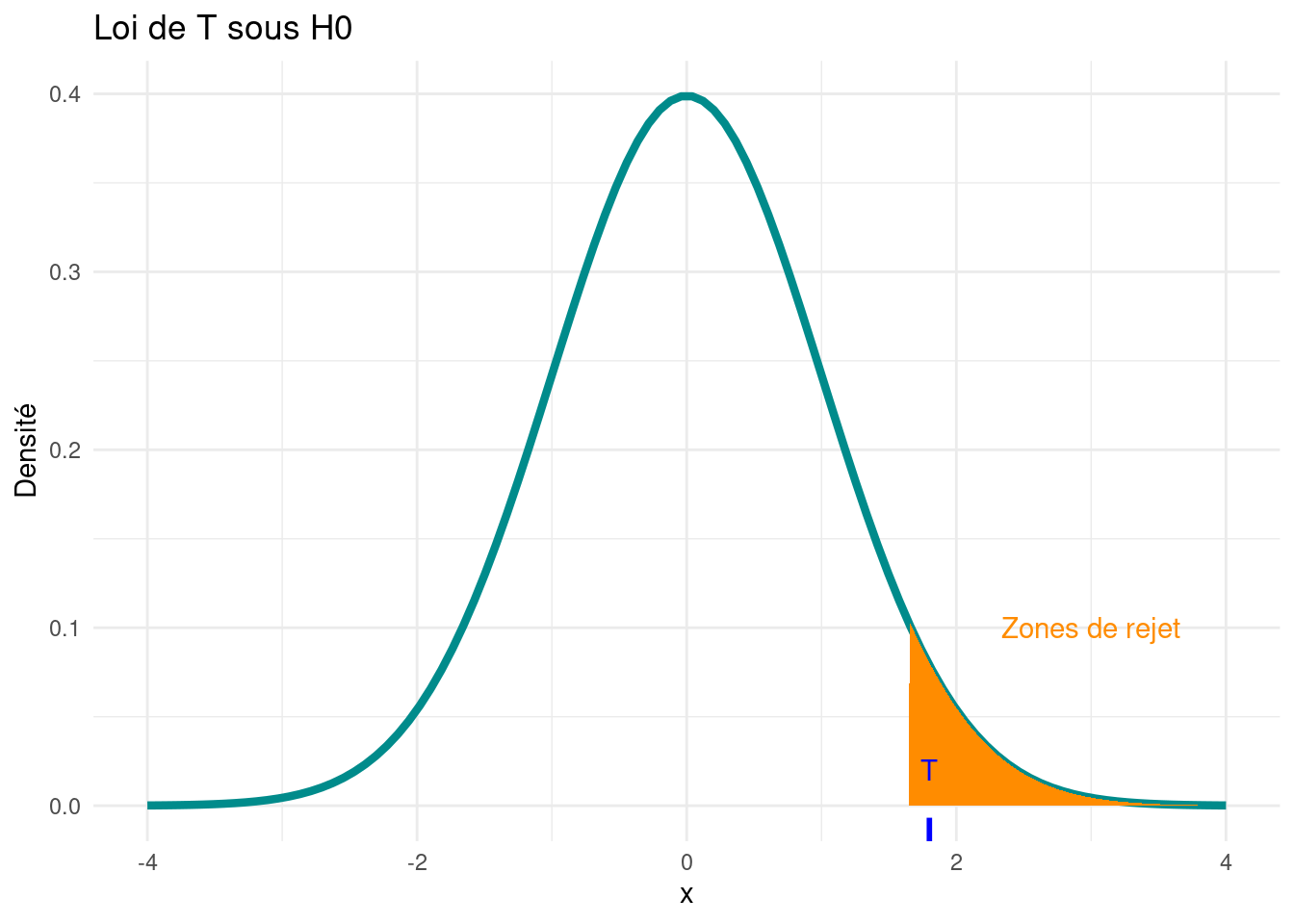
Nous rejetons si p est trop grand, donc la zone de rejet est :
c(qnorm(1- alpha), Inf)
[1] 1.644854 Inf
Est-ce que l’on rejette \(H_0\) ?
T >qnorm(1- alpha)
[1] TRUE
Au niveau de risque 0.05, nous rejetons \(H_0\) et donc la pièce est truquée côté pile.
Représentation graphique :
Code ggplot
# Données pour la courbe de densité normalex_values <-seq(-4, 4, length.out =100)y_values <-dnorm(x_values)# Données pour les zones de rejetzone_rejet_droite <-seq(qnorm(1-alpha), 4, 0.01)# Création du graphique avec ggplot2ggplot() +geom_line(data =data.frame(x = x_values, y = y_values), aes(x, y), color ="darkcyan", linewidth =1.5) +geom_polygon(data =data.frame(x =c(zone_rejet_droite, zone_rejet_droite[length(zone_rejet_droite)]), y =c(0, dnorm(zone_rejet_droite))), aes(x, y), fill ="darkorange") +geom_rug(data =data.frame(T = T), aes(x = T), sides ="b", color ="blue", linewidth =1) +xlim(-4, 4) +labs(x ="x", y ="Densité", title ="Loi de T sous H0") +theme_minimal() +scale_fill_manual(values ="darkorange", guide =FALSE) +guides(color ="none") +annotate("text", x =3, y =0.1, label ="Zones de rejet", color ="darkorange") +annotate("text", x = T, y =0.02, label ="T", color ="blue") +theme(legend.position ="none")