Exercices vintages 💾
Introduction
Lors du premier TP, nous avons utilisé DuckDB pour lire les données d’un fichier parquet. Aujourd’hui nous allons créer notre propre base de données PostgreSQL, puis y déclarer des tables et insérer de données. Enfin nous allons requêter ces données.
Lors de ce TP, vous allez :
- Créer votre base de données PostgreSQL
- Lancer des scripts de création de tables et d’insertion de données
- Relier des tables en utilisant les jointures
- Sélectionner et filtrer des données
- Écrivez des requêtes jolies !
- À la fin du TP, exportez ou copiez vos requêtes dans un fichier de votre VM ou machine personnelle
1 Lancement des services
Pour plus de détails, allez dans l’onglet Datalab.
-
- ouvrez ce service
- vérifiez que vous êtes connectés à la base de données PostgreSQL
- ouvrez la connexion (clic droit > Open), un petit rond vert apparait 🟢
cloudBeaver est parfois capricieux, en cas de blocage, n’hésitez pas à rafraichir la page (F5).
En attendant le lancement des services, voici un peu de lecture ci-dessous.
2 Méthodo : Écrire une requête
Il est parfois difficile d’écrire du premier coup LA requête qui répond directement à la question posée.
Voici une méthode qui peut vous aider à écrire vos requêtes pas à pas :
2.1 Listez les tables nécessaires
Commençons par lister les tables nécessaires, puis joignons-les.
Nous avons besoin ici des 2 tables que nous pouvons joindre en utilisant la colonne id_club.
SELECT *
FROM joueuse j
JOIN club c USING(id_club);- Nous utilisons pour l’instant
SELECT *pour sélectionner toutes les colonnes- nous enleverons les colonnes inutiles plus tard
- Nous utilisons des alias, cela rendra la requête plus courte et plus claire
- j pour joueuse
- c pour club
2.2 Appliquez les filtres
Filtrons pour ne conserver que les lignes qui nous intéressent.
- Ville du club : Saint Quentin
- Prénom qui commence par un A
SELECT *
FROM joueuse j
JOIN club c USING(id_club)
WHERE c.ville = 'Saint Quentin'
AND j.prenom LIKE 'A%';2.3 Ordonnez les résultats
Ordonnons par elo décroissant.
SELECT *
FROM joueuse j
JOIN club c USING(id_club)
WHERE c.ville = 'Saint Quentin'
AND j.prenom LIKE 'A%'
ORDER BY j.elo DESC;2.4 Sélectionner les colonnes requises
Il est demandé de ne garder que les noms et prénoms des joueuses.
Remplaçons le SELECT * par les noms des colonnes.
SELECT j.nom,
j.prenom
FROM joueuse j
JOIN club c USING(id_club)
WHERE c.ville = 'Saint Quentin'
AND j.prenom LIKE 'A%'
ORDER BY j.elo DESC;Maintenant, place à quelques exercices historiques.
3 Exercices
3.1 École de musique 🎸
Nous allons commencer par créer les tables et insérer les données :
-
- Cliquez sur la petite icone sous les triangles oranges qui ressemble à 📜
- raccourci (ALT + X)
- En cas d’erreur, corrigez, puis relancez intégralement le script
-
- Dans l’explorateur : PostgreSQL ➡️ Databases ➡️ defaultdb ➡️ Schemas
- Clic droit sur Schemas ➡️ Refresh
Si tout est ok, vous n’avez plus besoin du script de création et d’insertion de données.
Voici le modèle de données :
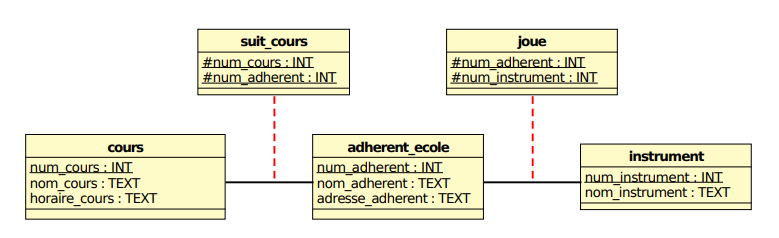
Vous pouvez maintenant commencer l’exercice et écrire les requêtes permettant de répondre aux questions suivantes :
Réalisez les jointures qui permettent d’obtenir :
3.2 Location de DVD 💿
Il fut un temps où des entreprises se spécialisaient dans la location de DVD. Dans cet exercice, une telle entreprise souhaite informatiser la gestion des prêts.
Voici le Modèle de données :
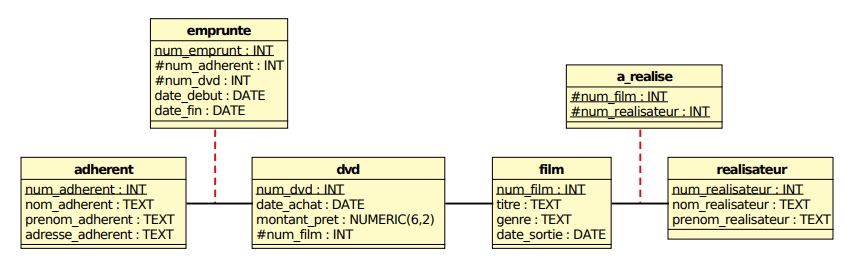
Création de tables
-
DROP SCHEMA IF EXISTS dvd CASCADE; CREATE SCHEMA dvd; CREATE TABLE dvd.realisateur( num_realisateur INT PRIMARY KEY, nom_realisateur TEXT, prenom_realisateur TEXT); CREATE TABLE dvd.film( num_film INT PRIMARY KEY, titre TEXT, genre TEXT, date_sortie DATE); CREATE TABLE dvd.a_realise( num_film INT REFERENCES dvd.film(num_film), num_realisateur INT REFERENCES dvd.realisateur(num_realisateur), PRIMARY KEY (num_film, num_realisateur));
Attention, ici l’ordre de création des tables a son importance.
Reprenons et modifions l’exemple ci-dessus :
- imaginez que vous essayez de créer en premier la table
a_realise - le champ num_film de cette table est une clé étrangère
- il référence la clé primaire num_film de la table
film - or si la table
filmn’existe pas, à votre avis, que va-t-il se passer ?
Requêtes
Donnez les requêtes pour obtenir :
Pour connaitre la version utilisée : SELECT version();
Pour les 3 requêtes suivantes, vous afficherez les noms et prénoms sur une seule colonne.
Utilisez le mot clé AS pour nommer cette colonne nom_complet à l’affichage.
Il existe différentes manières de concaténer du texte :
- fonctions PostgreSQL CONCAT(), CONCAT_WS()
- opérateur
||
Utilisons maintenant des méthodes d’agrégation pour répondre aux questions suivantes :
Quelques questions sur les dates :
Pour terminer cet exercice, nous allons rechercher les titres des films qui n’ont jamais été empruntés. Procédons par étapes et écrivez les requêtes suivantes :
3.3 Rugby World Cup 🏉
Nous souhaitons informatiser les résultats de la coupe du monde de rugby. Pour cela nous avons créé les deux tables suivantes : equipe et matches.
Commencez par créez et charger les tables avec ce script.
-
- Date du match
- Nom de la première équipe
- nombre de points de la première équipe
- nombre de points de la deuxième équipe
- nom de la deuxième équipe et lieu du match
Arrêtez vos services
C’est la fin du TP, vous pouvez maintenant sauvegarder votre travail et libérer les ressources réservées :